Types de réseaux P2P (Peer To Peer) et différences entre eux
La société d’aujourd’hui a besoin d’un échange d’informations abondant pour le développement de la plupart des activités ou des emplois. Par exemple, les entreprises, en particulier les multinationales, répartissent leurs projets parmi les nombreux sièges sociaux qu’elles ont dans le monde ; Cela signifie qu’il doit y avoir une communication et un échange d’informations entre les différents lieux pour le bon développement de leurs projets. Un autre exemple est celui des universités, qui ont besoin d’un système pour échanger des informations avec les étudiants, leur fournir des notes, des examens, etc.
C’est pourquoi vers 1996, la première application P2P a émergé des mains d’Adam Hinkley, Hotline Connect, qui se voulait un outil pour les universités et les entreprises pour la distribution de fichiers. Cette application utilisait une structure décentralisée et elle n’a pas tardé à devenir obsolète (car elle dépendait d’un seul serveur) ; et comme il a été conçu pour Mac OS, il n’a pas suscité beaucoup d’intérêt de la part des utilisateurs.
C’est avec Napster, en 1999, que l’utilisation des réseaux P2P a suscité la curiosité des utilisateurs. Ce système d’échange de musique utilisait un modèle de réseau hybride P2P, car outre la communication entre pairs, il incluait un serveur central pour organiser ces paires. Leur principal problème était que le serveur introduisait des points d’arrêt et une grande possibilité de goulots d’étranglement.
C’est pourquoi de nouvelles topologies telles que décentralisées font leur apparition, dont la principale caractéristique est de ne pas avoir besoin de serveur central pour organiser le réseau ; un exemple de cette topologie est Gnutella. Un autre type est celui des réseaux P2P structurés, qui se concentrent sur l’organisation du contenu plutôt que sur l’organisation des utilisateurs ; à titre d’exemple, nous soulignons JXTA. Nous avons également les réseaux avec Distributed Hash Table (DHT), tels que Chord.
Ensuite, nous développerons les types de réseaux P2P mentionnés ci-dessus.
Premiers systèmes P2P : une approche hybride
Les premiers systèmes P2P, tels que Napster ou SETI @ home, ont été les premiers à déplacer les tâches les plus lourdes des serveurs vers les ordinateurs des utilisateurs. A l’aide d’Internet, qui permet de combiner toutes les ressources fournies par les utilisateurs, ils ont réussi à faire en sorte que ces systèmes atteignent une plus grande capacité de stockage et une plus grande puissance de calcul que les serveurs. Mais le problème était que sans une infrastructure servant d’intermédiaire entre les entités homologues, le système deviendrait le chaos, car chaque homologue finirait par agir indépendamment.
La solution au problème de désordre est d’introduire un serveur central, qui sera chargé de coordonner les paires (la coordination entre paires peut varier fortement d’un système à l’autre). Ces types de systèmes sont appelés systèmes hybrides, car ils combinent le modèle client-serveur avec le modèle des réseaux P2P. Beaucoup de gens pensent que cette approche ne doit pas être décrite comme un véritable système P2P, car elle introduit un composant centralisé (serveur), mais malgré cela, cette approche a été et continue d’être très réussie.
Dans ce type de systèmes, lorsqu’une entité se connecte au réseau (à l’aide d’une application P2P), elle est enregistrée sur le serveur, de sorte que le serveur contrôle à tout moment le nombre de paires enregistrées sur ce serveur, leur permettant de proposer services à d’autres pairs. Normalement, la communication peer-to-peer se fait point à point, car les pairs ne forment pas de réseau majeur.
Le principal problème de cette conception est qu’elle introduit un point d’arrêt du système et une forte probabilité de ce que l’on appelle un « goulet d’étranglement » (en transfert de données, lorsque la capacité de traitement d’un appareil est supérieure à la capacité à laquelle l’appareil est connecté) . Si le réseau se développe, la charge du serveur augmentera également et si le système n’est pas en mesure de faire évoluer le réseau, le réseau s’effondrera. Et si le serveur tombe en panne, le réseau ne pourra pas se réorganiser.
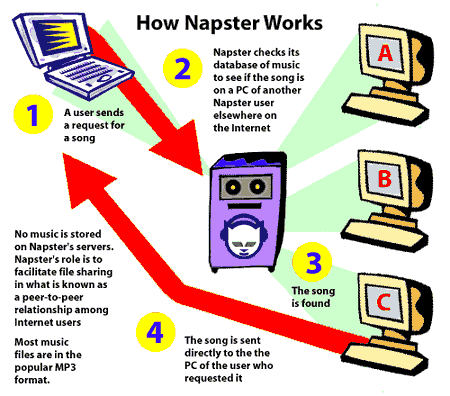
Mais malgré tout, il existe encore de nombreux systèmes qui utilisent ce modèle. Cette approche est utile pour les systèmes qui ne peuvent pas tolérer les incohérences et ne nécessitent pas de grandes quantités de ressources pour les tâches de coordination. À titre d’exemple, voici comment fonctionne Napster. Napster est né fin 1999, de la main de Shawn Fanning et Sean Parke, avec l’idée de partager des fichiers musicaux entre utilisateurs.
La façon dont Napster fonctionne est que les utilisateurs doivent se connecter à un serveur central, qui est chargé de maintenir une liste d’utilisateurs connectés et les fichiers disponibles pour ces utilisateurs. Lorsqu’un utilisateur veut obtenir un fichier, il fait une recherche sur le serveur et le serveur lui donne une liste de toutes les paires qui ont le fichier qu’il recherche. Ainsi, l’intéressé recherche l’utilisateur qui peut le mieux fournir ce dont il a besoin (en sélectionnant ceux qui ont le meilleur taux de transfert par exemple) et obtient son dossier directement auprès de lui, sans intermédiaire. Napster est rapidement devenu un système très populaire parmi les utilisateurs, atteignant 26 millions d’utilisateurs en 2001, provoquant un malaise parmi les maisons de disques et les musiciens.
C’est pourquoi la RIAA (Recording Industry Association of America) et plusieurs maisons de disques, pour tenter d’y mettre fin, ont déposé une plainte contre la société, ce qui a provoqué la fermeture de ses serveurs. Cela a provoqué un effondrement du réseau, car les utilisateurs ne pouvaient pas télécharger leurs fichiers musicaux. En conséquence, au lieu d’en finir avec le « piratage », une grande partie des utilisateurs ont migré vers d’autres systèmes d’échange comme Gnutella, Kazaa, etc.
Plus tard, vers 2008, Napster est devenu une société de vente de musique MP3, avec un grand nombre de chansons à télécharger : free.napster.com.
Réseaux P2P non structurés
Une autre façon de partager des fichiers est d’utiliser un réseau non centralisé, c’est-à-dire un réseau où tout type d’intermédiaire entre les utilisateurs est éliminé afin que le réseau lui-même se charge d’organiser la communication entre pairs.
Dans cette approche, si un utilisateur est connu, une «union» est établie entre eux, de sorte qu’ils forment un «réseau», auquel peuvent se joindre plusieurs utilisateurs. Pour trouver un fichier, un utilisateur lance une requête, qui inonde l’ensemble du réseau, afin de trouver le nombre maximum d’utilisateurs qui disposent de cette information.
Par exemple, pour effectuer une recherche dans Gnutella, l’utilisateur intéressé envoie une requête de recherche à ses voisins, et ceux-ci aux leurs. Mais pour éviter de faire s’effondrer le réseau avec une petite requête, l’horizon de diffusion est limité à une certaine distance de l’hôte d’origine et aussi la durée de vie de la requête, car à chaque fois que le message est transmis à un autre utilisateur, sa durée de vie diminue.
Le principal problème avec ce modèle est que si le réseau se développe, le message de requête n’atteindra que quelques utilisateurs. Si ce que nous recherchons est quelque chose de bien connu, n’importe quel hôte dans notre horizon de diffusion l’aura sûrement, mais d’un autre côté, si ce que nous recherchons est quelque chose de très spécial, nous ne le trouverons peut-être pas parce que l’horizon de diffusion est limité , nous aurons laissé de côté les hôtes qui contenaient peut-être les informations que nous recherchons.
À ce jour, les réseaux P2P purs non centralisés ont été remplacés par de nouvelles technologies, telles que les Supernodes .
SUPERNODOS, une hiérarchie en réseaux non structurés
Les principaux problèmes avec les réseaux non structurés étaient l’horizon de diffusion et la taille du réseau. Nous avons deux solutions possibles : soit on augmente l’horizon de diffusion, soit on diminue la taille du réseau. Si nous choisissons d’augmenter l’horizon de diffusion, nous augmentons le nombre d’hôtes auxquels nous devons envoyer le message de requête de manière exponentielle. Cela entraînerait, comme nous l’avons déjà vu, des problèmes dans le réseau, comme l’effondrement de celui-ci. Au contraire, si nous choisissons de réduire la taille du réseau, les systèmes sont capables de s’adapter beaucoup mieux sur le réseau, en utilisant les super-nœuds.
L’idée principale de ce système est que le réseau est divisé entre de nombreux nœuds terminaux et un petit groupe de super-nœuds bien connectés les uns aux autres, auxquels les nœuds terminaux sont connectés. Pour être un super-nœud, il faut pouvoir offrir suffisamment de ressources aux autres utilisateurs, notamment de la bande passante. Ce réseau de super-nœuds, dont seuls quelques-uns peuvent faire partie, est chargé de maintenir la taille du réseau suffisamment petite pour ne pas perdre en efficacité dans les recherches.
Son fonctionnement est similaire à celui du modèle hybride, puisque les nœuds terminaux sont connectés aux super-nœuds, qui jouent le rôle de serveurs, de sorte que les utilisateurs ne se connectent qu’avec d’autres utilisateurs pour effectuer exclusivement des téléchargements. Les super-nœuds stockent des informations sur ce que chaque utilisateur possède, de sorte qu’il puisse réduire le temps d’une recherche, en envoyant les informations aux nœuds terminaux qui ont ce que nous recherchons.
Ce type de structure est encore largement utilisé aujourd’hui, principalement parce qu’il est très utile pour échanger des informations sur des contenus populaires ou pour rechercher des mots-clés. Comme le réseau de super-nœuds est réduit, ces systèmes s’adaptent très bien à travers le réseau et n’offrent pas de points d’arrêt comme le modèle hybride. En revanche, ils diminuent la robustesse contre les attaques et les chutes de réseau et perdent en précision dans la recherche de résultats, du fait de la réplication via les super-nœuds. Si un petit nombre de super-nœuds échoue, le réseau est divisé en petites partitions.
Réseaux P2P structurés
Cette approche est développée en parallèle avec l’approche supernoeud décrite ci-dessus. Sa principale caractéristique est qu’au lieu de s’occuper d’organiser les nœuds, il se concentre sur l’organisation du contenu, en regroupant des contenus similaires sur le réseau et en créant une infrastructure qui permet une recherche efficace, entre autres.
Les pairs organisent entre eux une nouvelle couche réseau virtuelle, « un réseau superposé », qui se situe au-dessus du réseau P2P de base. Dans ce réseau superposé, la proximité entre les hébergeurs est donnée en fonction du contenu qu’ils partagent : ils seront d’autant plus proches les uns des autres qu’ils fourniront de ressources en commun. De cette façon, nous garantissons que la recherche est effectuée efficacement dans un horizon pas trop éloigné et sans réduire la taille du réseau. Par exemple, JXTA, où les pairs agissent dans un réseau virtuel et sont libres de former et de quitter des groupes de pairs. Ainsi, les messages de recherche restent normalement dans le réseau virtuel et le groupe agit comme un mécanisme de regroupement, combinant des paires ayant des intérêts identiques ou similaires.
Cette approche offre des performances élevées et des recherches précises, si le réseau virtuel reflète avec précision la similitude entre les nœuds en ce qui concerne les recherches. Mais il présente également une série d’inconvénients : il a un coût élevé d’établissement et de maintenance du réseau virtuel dans des systèmes où les hôtes entrent et sortent très rapidement ; ils ne sont pas très adaptés aux recherches qui incluent des opérateurs booléens, car des nœuds capables de rechercher avec plus d’un terme seraient nécessaires.
Une sous-classe de ce type de réseaux P2P est constituée de tables de hachage distribuées.
Tables de hachage distribuées (DHT)
La principale caractéristique des DHT est qu’elles n’organisent pas le réseau de superposition par son contenu ou ses services. Ces systèmes divisent tout leur espace de travail au moyen d’identifiants, qui sont attribués aux pairs qui utilisent ce réseau, les rendant responsables d’une petite partie de l’espace de travail total. Ces identifiants peuvent être, par exemple, des entiers compris dans l’intervalle [0, 2n-1], n étant un nombre fixe.
Chaque paire qui participe à ce réseau agit comme une petite base de données (l’ensemble de toutes les paires formerait une base de données distribuée). Cette base de données organise vos informations par paires (clé, valeur). Mais pour savoir quelle paire est chargée de sauvegarder cette paire (clé, valeur), nous avons besoin que la clé soit un entier dans la même plage avec laquelle les paires participantes du réseau sont numérotées. Étant donné que la clé peut ne pas être représentée dans les entiers, nous avons besoin d’une fonction qui convertit les clés en entiers dans la même plage avec laquelle les paires sont numérotées. Cette fonction est la fonction de hachage. Cette fonction a la particularité que face à des entrées différentes, elle peut donner la même valeur de sortie, mais avec une probabilité très faible. Alors au lieu de parler d’une «base de données distribuée»,
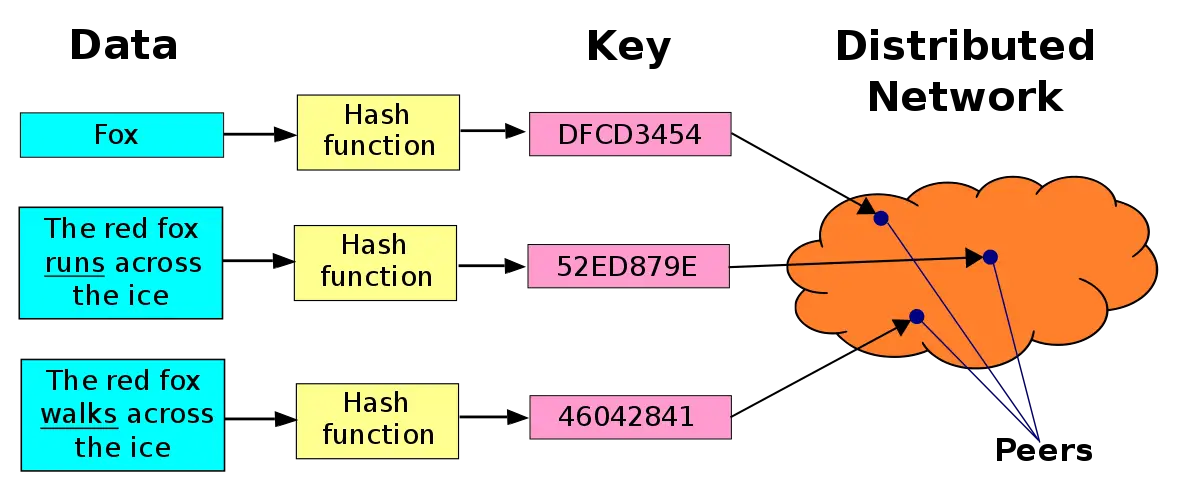
Nous avons déjà expliqué que chaque paire est responsable d’une partie de l’espace de travail du réseau. Mais comment mapper la paire (clé, valeur) à la bonne paire ? Pour ce faire, une règle est suivie : une fois le hachage de clé calculé, le couple (clé, valeur) est affecté au couple dont l’identifiant est le plus proche (le successeur immédiat) du hachage calculé. Dans le cas où le hachage calculé est supérieur aux identifiants des couples, la convention modulo 2n est utilisée.
Une fois que nous avons un peu parlé du fonctionnement de base de DHT, nous allons voir un exemple de sa mise en œuvre, à travers le protocole CHORD.
Protocole de recherche distribué dans les réseaux P2P : CHORD
Chord est l’un des protocoles de recherche distribuée les plus populaires sur les réseaux P2P. Ce protocole utilise la fonction de hachage SHA-1 pour attribuer, à la fois aux couples et aux informations stockées, leur identifiant. Ces identifiants sont disposés en cercle (prenant toutes les valeurs modulo 2m), afin que chaque nœud sache qui est son prédécesseur et son successeur le plus immédiat.
Afin de maintenir l’évolutivité du réseau, lorsqu’un nœud quitte le réseau, toutes ses clés passent à son successeur immédiat, de telle sorte que le réseau soit toujours tenu à jour, évitant ainsi que les recherches puissent être erronées.
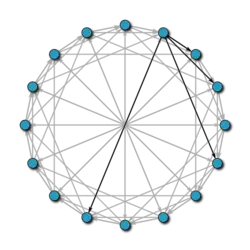
Pour trouver la personne qui stocke une clé, les nœuds s’envoient des messages jusqu’à ce qu’ils la trouvent. Mais, en raison de la disposition circulaire du réseau, dans le pire des cas, une requête peut passer par la moitié des nœuds, ce qui rend sa maintenance très coûteuse. Pour éviter cela, et ainsi réduire les coûts, chaque nœud dispose d’une table de routage stockée, dans laquelle est stockée l’adresse des nœuds qui sont à une certaine distance de lui. Ainsi, lorsque l’on veut savoir qui est en charge de la clé k, le nœud recherche dans sa table de routage s’il possède l’adresse du responsable de k ; si c’est le cas, il vous envoie directement la demande ; s’il ne l’a pas, il envoie la question au nœud le plus proche de k, dont l’identifiant est inférieur à k.
Avec cette amélioration, nous avons réussi à réduire le coût des recherches de N/2 à log N, où N est le numéro du nœud du réseau.
Conclusion
Comme nous l’avons vu, il existe de nombreux types de réseaux P2P, chacun avec ses forces et ses faiblesses. Aucune ne se démarque des autres, ce qui permet, lors de la programmation par exemple d’une application P2P, d’avoir plusieurs options, chacune avec ses propres caractéristiques.
Une chose à garder à l’esprit est l’évolution de la façon de partager l’information. À la fin du dernier millénaire, l’utilisation des réseaux P2P était abondante et, pour la plupart des gens, c’était le seul moyen connu de partager des informations. Aujourd’hui, la tendance a changé. Les gens préfèrent maintenant échanger des fichiers via de grands serveurs où, dans certains cas, ils paient des utilisateurs pour les héberger.
Certaines questions qui peuvent venir à l’esprit sont : Quel est l’avenir des réseaux P2P ? Vers quelles formes d’organisation de l’information évoluons-nous ?
Une des évolutions possibles est le passage du P2P au p4p. Qu’est-ce que le P4P ? En résumé nous dirons que le P4P, également appelé P2P hybride, est une petite évolution du P2P dont la principale caractéristique est que les fournisseurs de services, les FAI, forment un rôle essentiel au sein du réseau, car lorsqu’il s’agit de faire Une recherche cherchera d’abord parmi les nœuds participants qui appartiennent au même FAI.